Google Cloud Vision API ашиглан зургаас текстийг нуух
Нийтэлсэн:
Програм хангамжийн инженер Г.Эрдэнэтөгс
Хураангуй
Энэхүү бичвэрээр хэрхэн Google Cloud Vision API ашиглан зурган мэдээллээс зөвхөн текстийг нь ялгаж нуух талаар step-by-step дарааллаар орууллаа.
Асуудал
Зурган мэдээллээс текстийг нуух хэрэгцээ түгээмэл гардаг бөгөөд үүний нэг жишээ нь хэрэглэгчийн хувийн мэдээлэл гарсан зургийг (паспорт, жолооны үнэмлэх г.м) ямар нэгэн дотоодын системд ашиглах тохиолдолд хувь хүний мэдээллийг хамгаалах зорилгоор текстийг нуух тохиолдол юм. Иймэрхүү асуудал шийддэг сервисийг API (Application Programming Interface) байдлаар үүлэн технологийн компаниуд нээлттэй болгосон байдаг ба үүнд доорх сервисүүд ордог.
- Amazon Rekognition
- Microsoft Azure Computer Vision API
- IBM Watson Visual Recognition
- Google Cloud Vision API
Тэгвэл бид энэ удаа Google Cloud Vision API ашиглах болно.
Шийдэл
Хамгийн түрүүнд Google Cloud Vision API ийг дуудахын тулд бид хэд хэдэн тохиргоо хийх хэрэгтэй.
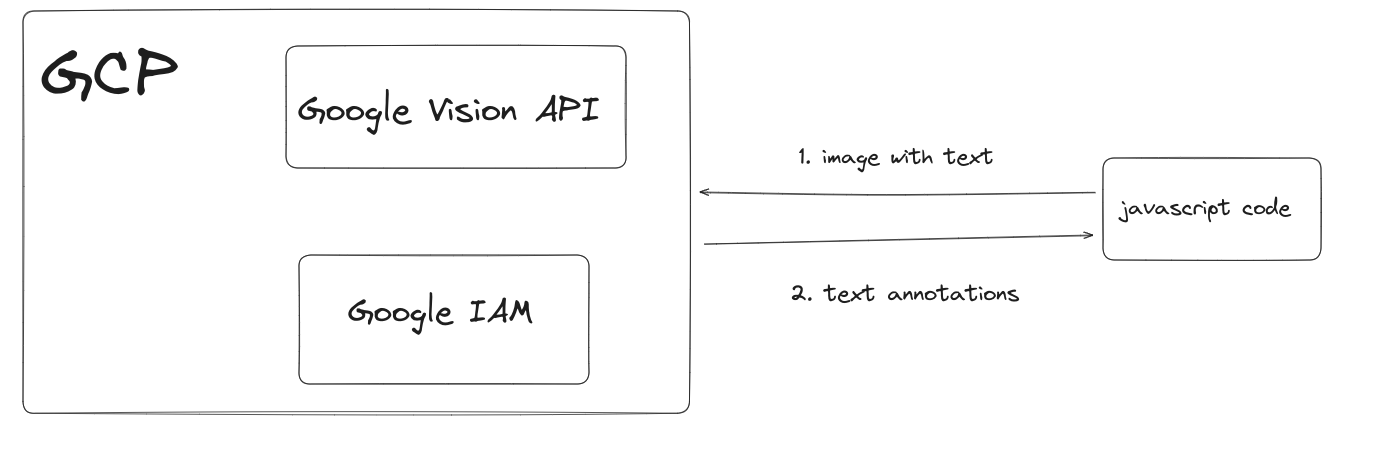
Тохиргоо хийх дараалал:
- Google Cloud Console дээр өөрийн прожект нээх. Заавар
- Vision API-аа идэвхжүүлэх. Заавар
- Google Cloud Console-оос Service Account нээх. Заавар
- Service Account гэдэг нь GCP (Google Cloud Platform)-н сервисүүдийг ашиглах эрхтэй тусгай user account юм.
- IAM API-ийг идэвхжүүлэх. Заавар (IAM нь Google cloud-н сервисүүдийн хандах эрхийн зохицуулалт хийдэг сервис)
- Service Account үүсгэх. Заавар
Зураг 1. Service account нээх
- Service account-даа зохих permission-г (Storage Object Viewer) өгөх.
Зураг 2. Зохих permission өгөх
- Service account дээр key үүсгэж хадгалах
Зураг 3. Service account key үүсгэх
Ингэснээр бид Google Cloud Vision API-ийг өөрийн орчин дээрээ дуудах боломжтой болгож байгаа юм. Одоо Vision API-руугаа зурган мэдээллээ оруулаад түүнд байгаа текстийг таних тэгээд тухайн текстийн байршлыг ашиглан өнгөөр будах маягаар нуух асуудал үлдэж байгаа юм.
Шийдэл маань ерөнхийдөө 2 хэсгээс бүрдэж байгаа.
- Зургаас текстийг таних
- Текстийг өнгөөр будах маягаар нуух
Энэ шийдлээ хэрэгжүүлэхийн тулд javascript ашиглах ба прожектын бүтцээ тодорхойлж, хэрэгтэй library-гаа суулгах болно.
- Доорх дарааллаар прожектоо үүсгэнэ
1. mkdir text-erase (project-н root folder үүсгэх) 2. cd text-erase (project-н folder-луу орох) 3. npm init -y (node project үүсгэх) 4. mkdir resources (бичвэр таних зураг аа оруулах folder үүсгэх) 5. mkdir dist (үр дүнгээ оруулах folder үүсгэх) 6. touch index.js 7. Бичвэр таних зургийг `resources/image.png` path-руу хуулах 8. Өмнөх үүсгэсэн service account key-г project root folder-луу хуулж, vision-api-key.json гэж нэрлэх
2. Хэрэгцээтэй 3rd party libraries-г суулгах
npm install --save @google-cloud/vision canvas- Canvas (image editing буюу текст нуух хэсэгт хэрэг болно)
- @google-cloud/vision (official google cloud vision sdk)
3. Folder-н бүтэц доорх байдлаар харагдах болно
text-erase ├── dist -> script-с гарсан үр дүн ├── node_modules -> npm install command automate-р үүсгэнэ ├── resources -> script ажиллахад хэрэгтэй file-ууд │ └── image.png -> эх зураг ├── index.js -> main script ├── package.json -> npm init -y command automate-р үүсгэнэ ├── package-lock.json -> npm install command automate-р үүсгэнэ └── vision-api-key.json -> vision api ашиглах service account
4. Доорх хэсэгт хэрхэн google vision library-аар зураас текстийг таньж бичвэр танилтын үр дүнг хадгалж байна
index.js // google vision library-г import хийх const vision = require('@google-cloud/vision'); // fs буюу filesystem library-г import хийх // дараа нь text-үүдийн result-г цэгцтэй харах үүднээс const fs = require('fs'); // vision api-г ашиглахын тулд өмнө үүсгэсэн service account-н key-г зааж өгөх const client = new vision.ImageAnnotatorClient({ keyFile: './vision-api-key.json' }); const main = async () => { // бичвэр таних зургийн замаа зааж өгөөд documentTextDetection method-г дуудах const [result] = await client.documentTextDetection('./resources/image.png'); // Үр дүн ирэхгүй байх үеийг шалгах if (result.textAnnotations.length === 0 || result.textAnnotations == null) { console.log('No text detected in the image.'); return; } // dist folder-луу бичвэр танилтын үр дүнг хадгалах fs.writeFileSync('./dist/annotation-result.json', JSON.stringify(result, null, 2)); }; main();
Харин одоо бид нэгэнт зурган мэдээллээсээ текстийг таньж чаддаг болсон учраас тухайн текст бүрийг өнгөөр будах байдлаар нуух ажил үлдлээ. Түүний тулд буцаагдаж байгаа үр дүнг (result) ойлгох хэрэгтэй.
Result утгын гол бүтэц:
- textAnnotations: бичвэрээс олдсон текстүүдийн талаар мэдээлэл
- textAnnotation: бичвэрээс олдсон текстийн талаар мэдээлэл
- Description: бичвэрээс олдсон текст
- boundingPoly: бичвэрийг хүрээлсэн polygon-ы мэдээлэл
- Vertices: polygon-ы оройнуудын мэдээлэл
- Vertex: оройн мэдээлэл
- x : x coordinate
- y : y coordinate
- Vertex: оройн мэдээлэл
5. Доорх script нь зургаас текстийг таньж хар өнгөөр будах байдлаар нуух болон үр дүнгээ dist folder-луу гаргах хүртэл бүтэн үйл явцыг агуулах болно.
const vision = require('@google-cloud/vision'); const fs = require('fs'); const { createCanvas, loadImage } = require('canvas'); const client = new vision.ImageAnnotatorClient({ keyFile: './vision-api-key.json' }); const IMAGE_SIZE = 320; const CENSOR_COLOR = '#000000'; const main = async () => { const [result] = await client.documentTextDetection('./resources/image.png'); if (result.textAnnotations.length === 0 || result.textAnnotations == null) { console.log('No text detected in the image.'); return; } // canvas үүсгэх const canvas = createCanvas(IMAGE_SIZE, IMAGE_SIZE); const ctx = canvas.getContext('2d'); // зурагаа load хийх const image = await loadImage('./resources/image.png'); // зурагаа canvas дээр зурах ctx.drawImage(image, 0, 0, IMAGE_SIZE, IMAGE_SIZE); // canvas-н зураг дээр засвар оруулах өнгийг зааж өгөх ctx.fillStyle = CENSOR_COLOR; // эхний result зураг дээрхи бүх text-г харуулдаг тул үлдсэн result-уудыг ашиглах const [_fullAnnotation, ...textAnnotations] = result.textAnnotations; // бичвэр таньсан result бүр дээр path зурж хар fillStyle дээр өгөгдсөн өнгөөр дүүргэх textAnnotations.forEach(textAnnotation => { if (textAnnotation.boundingPoly == null || textAnnotation.boundingPoly.vertices == null) { return; } // таньсан зургийн захын цэгүүдийн coordinate бүрийг canvas дээр оруулах textAnnotation.boundingPoly.vertices.forEach((vertex, index) => { // эхний coordinate дээр шинэ path эхлүүлж cursor-г coordinate-руу зөөх if (index === 0) { ctx.beginPath(); ctx.moveTo(vertex.x, vertex.y); return; } // бусад дээр өмнөх coordinate-с одоогийн coordinate-рүү шулуун татах ctx.lineTo(vertex.x, vertex.y); }); // path-г хааж өнгөөр дүүргэх ctx.closePath(); ctx.fill(); }); // canvas-г buffer болгож dist folder-луу бичих const buffer = canvas.toBuffer(); fs.writeFileSync('./dist/text-erased-image.png', buffer); }; main();
Үр дүн
Дүгнэлт
Энэхүү бичвэртээ зургаас текст нуух ямар шаардлага гардаг, нуухын тулд Google Cloud Vision API сервисийг хэрхэн ашиглаж хэрэгжүүлэх талаар мэдээллүүдээ нэгтгэн хүргэлээ.